Websites and applications use databases to permanently store data to be retrieved at a later time. The data to be stored could be user credentials, photos, product information, status updates, tweets, or anything else. The main consideration for any type of database is its scalability, or the ability to process more data with increasing frequency. Over the past 40 years, two types of databases have emerged for storing data – SQL databases and NoSQL databases.
SQL databases
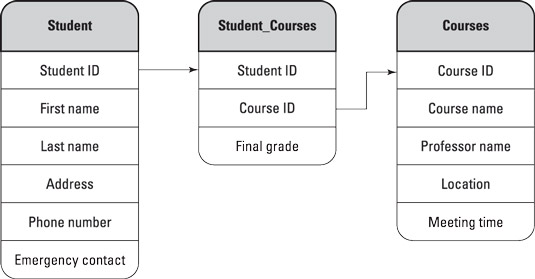
SQL, or Structured Query Language, is the standard language for relational databases. A relational database stores data in column and row tables, with a unique key assigned to each row. This unique key is then used to create relationships between data in related tables. For example, if a university is building a student database, it can create the following:
>> Student schedule with student’s first and last name, address information, phone number and emergency contact information. Each student will also have a unique key (student ID).
>> Student course schedule with each student’s unique key, course unique key (course ID), and student’s final mark.
>> Course schedule with course unique key, course name, professor name, location and meeting time.
Tables and the predefined relationship between data items make a relational database. You might be wondering why multiple tables are needed, when instead you could represent all the information in one big table. Two reasons are data consistency and data accuracy.
If the course name has changed and you are using one large table, you will have to find and change all instances of the course name. With a single course schedule, you can change the course name only once. SQL databases work best when the data is not redundant and is instead joined using multiple tables.
The SQL programming language accesses and modifies databases by using SQL queries. A SQL query is inserted into the code of the programming language you’re using (Ruby, Python, or PHP), and the results of the query are then output to your website or data analytics program. If you’re setting up the database yourself, you might want to install a popular database management system such as MySQL or PostgreSQL. Alternatively, if you’re using a BAAS provider for your application, your database can be installed automatically.
NoSQL databases
NoSQL databases take advantage of advances in hardware to build faster and more efficient databases. Historically, CPUs and storage were expensive, so databases were designed to minimize cost and resources used. If the database grew too large, or the queries started running slowly, the database was moved to a more powerful computer with additional storage.
Today, two things have happened that challenge assumptions used by SQL databases. First, hardware prices of storage and CPUs have dropped, while hard drives have become bigger and CPUs have become more powerful. Second, the amount of data that needs to be stored has increased, and it is not always clear in advance what data will be collected and stored.
For example, Google processes 24 petabytes (1000 terabytes) of data daily — the average consumer hard drive is a little over 1 terabyte.
NoSQL databases are distributed, which means they are stored and processed across multiple servers. Popular NoSQL databases include MongoDB, CouchDB, and Redis. A NoSQL database system has the following advantages:
No schema: Unlike with a SQL database, you do not define the data relationships beforehand. NoSQL databases allow you to change the format or type of data being stored at any time.
Scalable: If your database becomes too large, you can easily add another relatively cheap server without any downtime. For SQL databases, scaling your database requires buying an expensive server and experiencing downtime to migrate and install the database on a new system.
Cheap: You can use inexpensive consumer‐level hardware for a NoSQL database. For even greater ease, you can use a product such as Amazon web Services (AWS) to cheaply rent storage space and set up a NoSQL database with just a click, without buying physical servers.
NoSQL databases also spread the processing load across multiple CPUs. In a process called MapReduce, a large data set is divided into smaller data sets, which are each processed independently. The results from these individual data sets are then reduced back into a single data set or result.
For example, suppose you want to find the Facebook user with the most friends. Instead of using one computer to search Facebook’s 1.5 billion users, you could split the users into fifteen data sets of 100,000 users each, and then map each data set to one of fifteen computers.
Each computer would process its list to find the user with the most friends, after which each result would be reduced into one smaller data set of fifteen names. The final operation would find the user with the most friends from this smaller list of fifteen users.
NoSQL databases have many advantages, but there are some obstacles as well. The database system is relatively new, so there is less technical support and fewer people with expertise to set up, administer, and develop NoSQL databases. Additionally, because running simple queries in NoSQL databases can be difficult, doing analytics and business reporting for NoSQL databases is not as developed and is much harder than doing similar work for SQL databases.